Tracing MongoDB Atlas Vector Search with Langtrace

Ali Waleed
⸱
Software Engineer
Nov 12, 2024

Introduction
In modern data-driven applications, vector search is becoming increasingly popular for handling complex data queries. MongoDB Atlas’s new vector search feature allows users to perform similarity searches on vector embeddings, which is especially useful in applications like recommendation engines, NLP, and image search. However, understanding the performance and operations behind vector search queries can be challenging. Here, Langtrace steps in as a robust observability solution, allowing us to trace and analyze MongoDB Atlas’s vector search queries in real-time.
In this blog, we’ll walk through a hands-on example of how to integrate Langtrace with MongoDB Atlas to trace vector search operations, providing valuable insights into each stage of the query.
Setting Up the Environment
For this example, we’ll use MongoDB’s mflix sample dataset, which provides a collection of movies that’s perfect for testing vector search operations. This dataset can be loaded directly into your MongoDB Atlas cluster by following the instructions in the link.
To keep our project dependencies isolated, we’ll set up a virtual environment. This helps avoid conflicts between libraries, especially when working across different projects.
Activate the virtual environment
Once the environment is activated, you can install the required libraries, which include pymongo, langtrace_python_sdk, openai
With the environment set up and libraries installed, we’re ready to connect to MongoDB and integrate Langtrace for tracing.
Connecting to MongoDB Atlas with pymongo
To connect securely to MongoDB Atlas, we’ll use pymongo alongside environment variables to keep our credentials safe.
1. Create a .env file in your project directory to store sensitive information like your MongoDB URI
Connect to pymongo cluster.
Now we can access the collection using
Creating a Helper Function to Generate Embeddings
To perform vector searches, we need to generate vector embeddings for our queries. For this example, we’ll use the text-embedding-ada-002 model from OpenAI, which is optimized for generating text embeddings.
These embeddings will be used in our MongoDB Atlas vector search as the queryVector, allowing us to find similar documents based on text similarity.
With this helper function ready, we can now move to the next part: constructing the vector search query in MongoDB and integrating it with Langtrace for tracing.
Building the Vector Search Query with MongoDB Atlas
With our MongoDB connection and embedding helper function in place, we’re ready to create the main function that performs the vector search. This function will use MongoDB’s $vectorSearch stage within an aggregation pipeline to find similar documents based on vector embeddings. We’ll wrap this function with Langtrace to capture and trace the entire search operation.
Define the Vector Search Function
Running the Vector Search
Aggregation Pipeline
• $vectorSearch: Searches for documents similar to the specified queryVector, which we generate using our get_embedding function. We specify the index and path to the field storing embeddings (plot_embedding).
• $project: Selects specific fields to return in the result, such as the plot, title, and similarity score.
Adding Langtrace to the mix
Go to langtrace.ai and create an account
Create a new project and save your api key
Initialize langtrace
Use
with_langtrace_root_spandecorator to group spans together
Analyze traces
Here you see the trace overview stating vendors and embedding's model & value

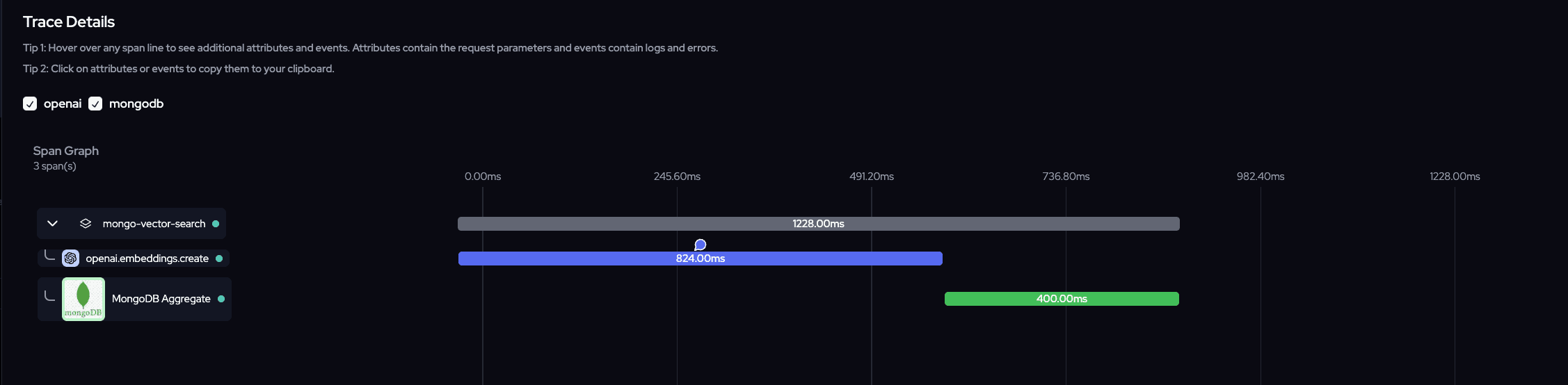
Here you see the overview of spans and order of execution, having a timeline to analyze latency and time to finish
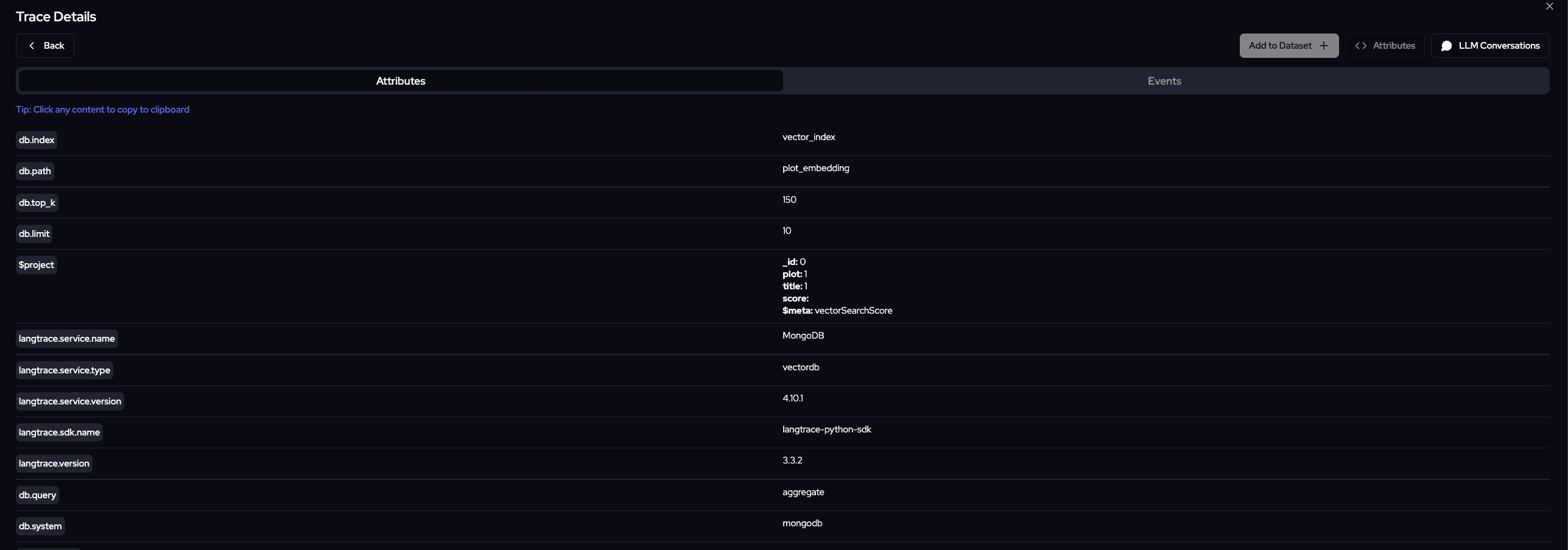
Here you see attributes traced using mongodb's
aggregatemethod
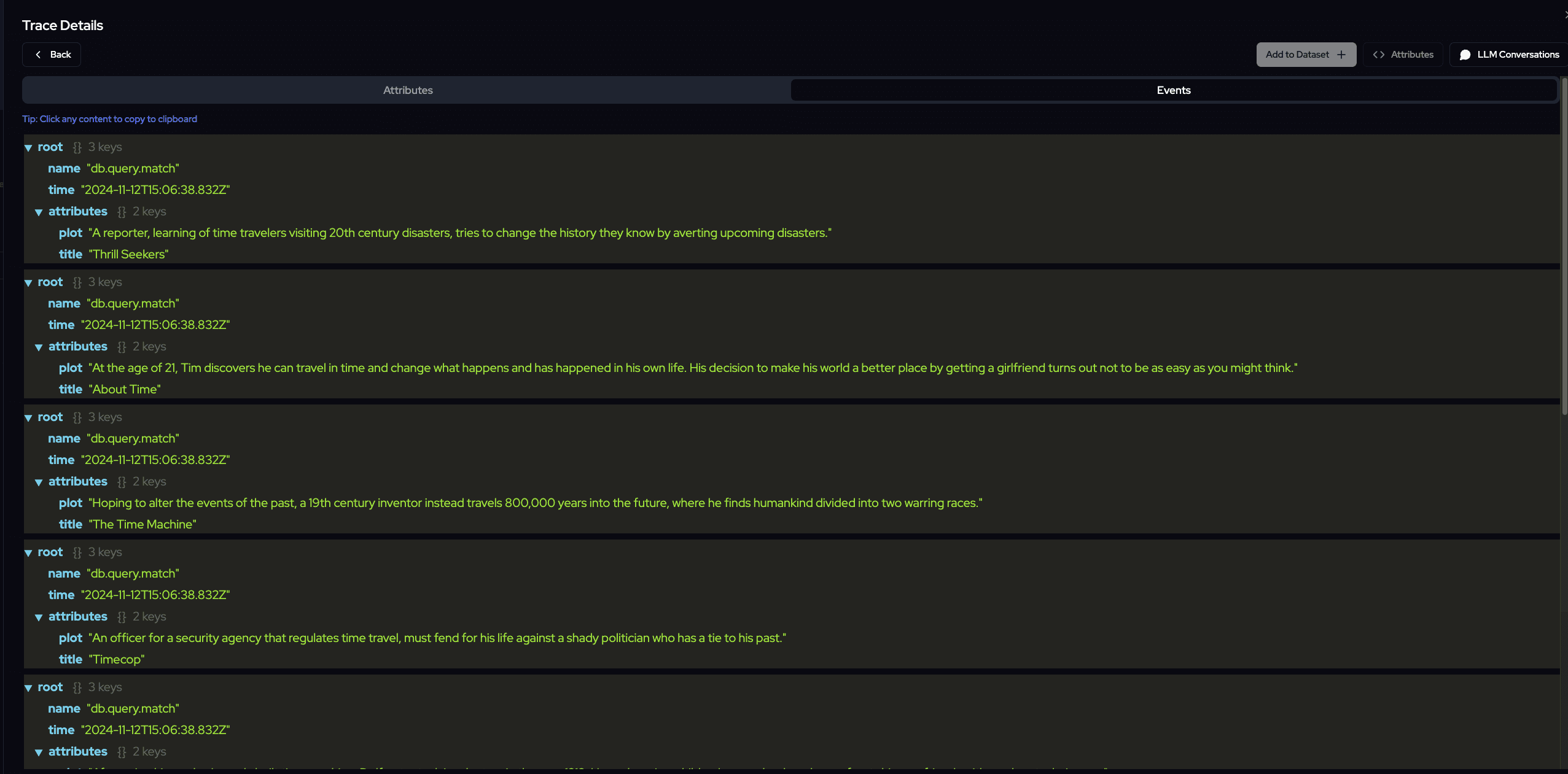
Here you see the events traced, which highlights the matches returned back as a result from mongodb's query vector search
Conclusion
Integrating Langtrace with MongoDB Atlas’s vector search feature opens up a powerful approach to observability in complex, AI-driven applications. By tracing each stage of the vector search, from embedding generation to query execution, Langtrace provides crucial insights that empower developers to monitor and optimize their system’s performance.
With this setup, you can now:
• Gain visibility into MongoDB Atlas vector search operations.
• Monitor query performance metrics in real time.
• Identify potential bottlenecks and improve overall system efficiency.
As vector search continues to expand across various applications, having this level of insight will be essential for maintaining responsive and reliable systems. For your next steps, consider experimenting with different embedding models, increasing the complexity of your aggregation pipeline, or extending Langtrace to trace additional parts of your stack for even deeper observability.
Happy tracing with Langtrace and MongoDB!
Useful Resources
Getting started with Langtrace https://docs.langtrace.ai/introduction
Langtrace is an official MongoDB ecosystem partner https://cloud.mongodb.com/ecosystem/langtrace-ai
Langtrace Website https://langtrace.ai/
Langtrace Discord https://discord.langtrace.ai/
Langtrace Github https://github.com/Scale3-Labs/langtrace
Langtrace Twitter(X) https://x.com/langtrace_ai
Langtrace Linkedin https://www.linkedin.com/company/langtrace/about/
Ready to deploy?
Try out the Langtrace SDK with just 2 lines of code.
Want to learn more?
Check out our documentation to learn more about how langtrace works
Join the Community
Check out our Discord community to ask questions and meet customers
